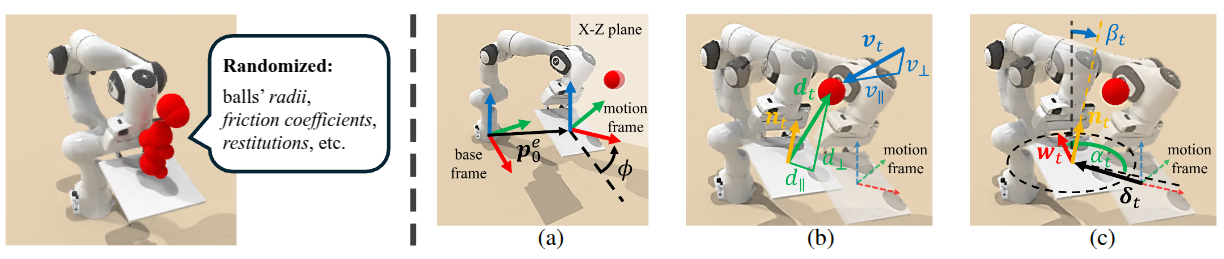
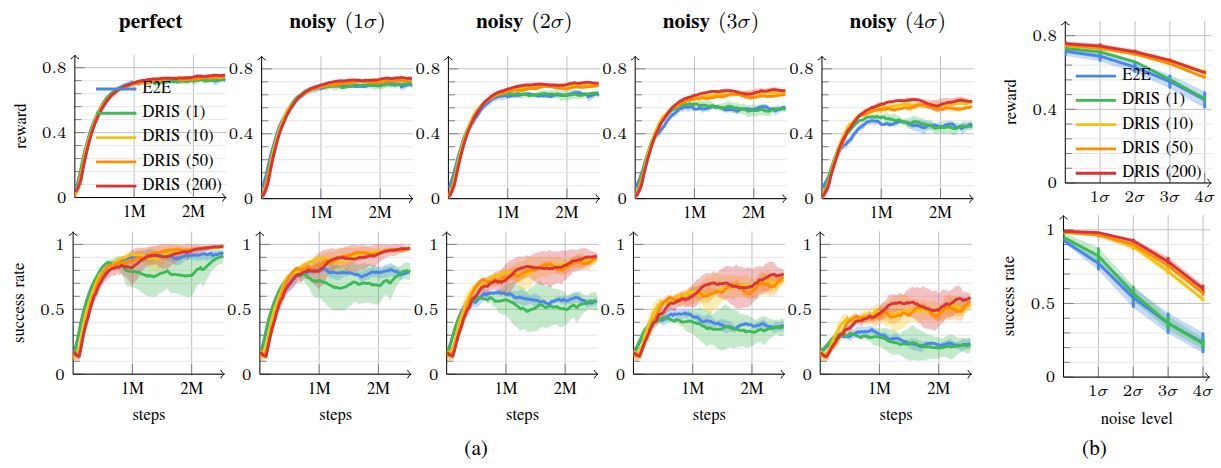
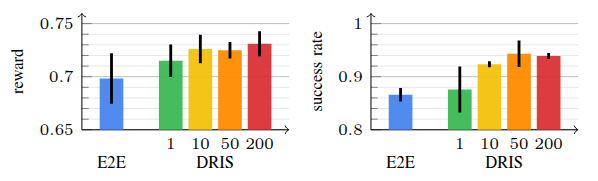
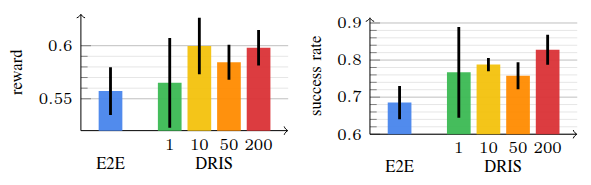
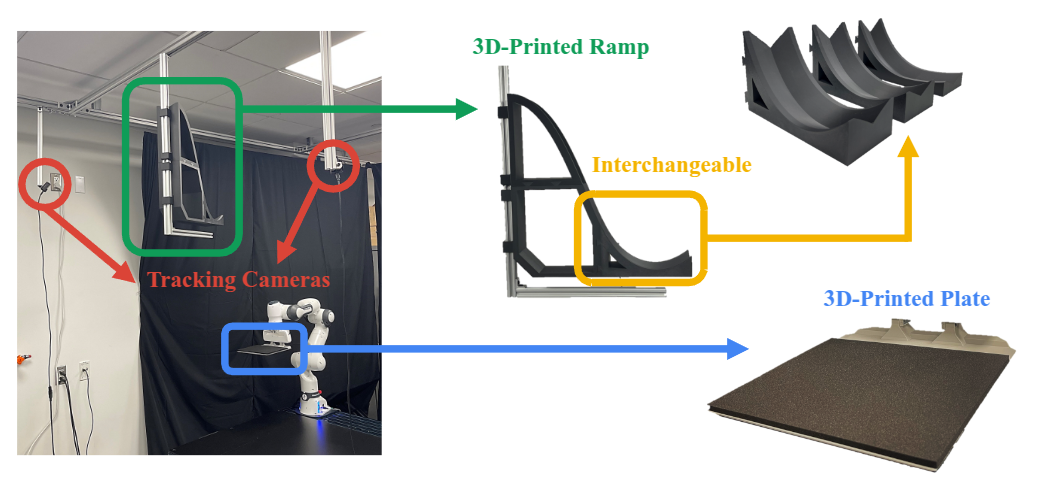
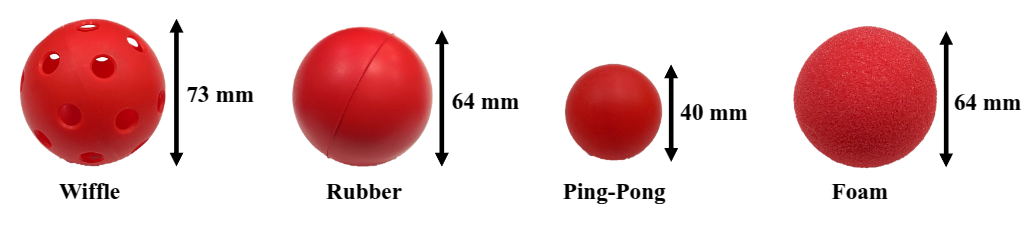
Method: Domain-Randomized Instance Set (DRIS)
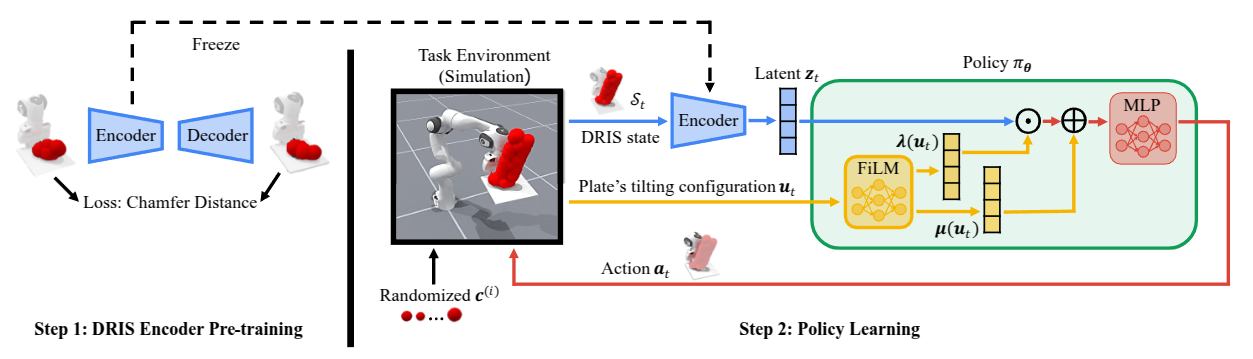
Step 1: Pre-train the DRIS encoder via autoencoder reconstruction. Step 2: Train a FiLM-conditioned policy via RL using the frozen encoder.
DRIS
Propagates N parallel instances with different physical properties simultaneously;
their joint evolution under a shared action informs a single policy update.
Set Encoder
A point-cloud autoencoder maps the DRIS state to a fixed-dimensional
latent zt, invariant to DRIS size N.
FiLM Policy
Conditions the latent state on the plate's current tilt via feature-wise affine modulation,
enabling consistent control across plate orientations.
Zero-Shot Transfer
At deployment, the single real-world observation is treated as DRIS of size N = 1 —
no real-world fine-tuning needed.